9.4 Measurement quality
Learning Objectives
- Define reliability and describe the types of reliability
- Define validity and describe the types of validity
- Analyze the rigor of qualitative measurement using the criteria of trustworthiness and authenticity
Once we’ve defined our terms and specified the operations for quantitatively measuring them, how do we know that our measures are any good? Without some assurance of the quality of our measures, we cannot be certain that our findings have any meaning or that our findings mean what we think they mean. When social scientists measure concepts, they aim to achieve reliability and validity in their measures. These two aspects of measurement quality are the focus of this section. First, we will consider reliability and later look at validity. Let’s say our interest is in measuring the concepts of alcoholism and alcohol intake. What are some potential problems that could arise when attempting to measure this concept, and how might we work to overcome those problems?

Reliability
First, let’s say we’ve decided to measure alcoholism by asking people to respond to the following question: Have you ever had a problem with alcohol? If we measure alcoholism this way, then it is likely that anyone who identifies as an alcoholic would respond “yes.” This may seem like a good way to identify our group of interest, but think about how you and your peer group may respond to this question. Would participants respond differently after a wild night out, compared to any other night? Could an infrequent drinker’s current headache from last night’s glass of wine influence how they answer the question this morning? How would that same person respond to the question before consuming the wine? In each cases, the same person might respond differently to the same question at different points, so it is possible that our measure of alcoholism has a reliability problem. Reliability in measurement is about consistency.
One common problem of reliability with social scientific measures is memory. If we ask research participants to recall some aspect of their own past behavior, we should try to make the recollection process as simple and straightforward for them as possible. Sticking with the topic of alcohol intake, if we ask respondents how much wine, beer, and liquor they’ve consumed each day over the course of the past 3 months, how likely are we to get accurate responses? Unless a person keeps a journal documenting their intake, there will very likely be some inaccuracies in their responses. On the other hand, we might get more accurate responses if we ask a participant how many drinks of any kind they have consumed in the past week.
Reliability can be an issue even when we’re not reliant on others to accurately report their behaviors. Perhaps a researcher is interested in observing how alcohol intake influences interactions in public locations. They may decide to conduct observations at a local pub by noting how many drinks patrons consume and how their behavior changes as their intake changes. What if the researcher has to use the restroom, and the patron next to them takes three shots of tequila during the brief period the researcher is away from their seat? The reliability of this researcher’s measure of alcohol intake depends on their ability to physically observe every instance of patrons consuming drinks. If they are unlikely to be able to observe every such instance, then perhaps their mechanism for measuring this concept is not reliable.
If the measure yields consistent results when given multiple times, then the measure is considered to reliable. For example, if you took the SATs on multiple occasions before coming to school, your scores should be relatively the same from test to test. This is what is known as test-retest reliability. In the same way, a person who suffers from clinical depression should score similar results on a depression scale today and a few days from now.
Additionally, you may need to assess inter-rater reliability if your study involves observing people’s behaviors. Inter-rater reliability is the degree to which different observers agree on what happened. For instance, let’s say your study involves observing sessions of mothers interacting with infants. Did you miss when the mother dismissed the infant when he was offering her an object? Did the other person rating miss that event? Do you both similarly rate the parent’s engagement with the child? Again, scores of multiple observers should be consistent, though perhaps not perfectly identical.
Finally, internal consistency reliability is an important concept when dealing with scales. The scores on each question of a scale should be correlated with each other, as they all measure parts of the same concept. Think about a scale of depression, like Beck’s Depression Inventory (BDI). A person who is depressed would score highly on most of the measures, but there would be some variation. For example, we would imagine that there would be a correlation between scores on mood disturbance and lack of enjoyment if we administered the BDI to a group. They aren’t the same concept, but they are related, so there should be a mathematical relationship between them. A specific statistical test known as Cronbach’s Alpha provides a way to measure how well each question of a scale is related to the others.
Test-retest, inter-rater, and internal consistency are three important subtypes of reliability. Researchers use these types of reliability to make sure their measures are consistently measuring the concepts in their research questions.
Validity
While reliability is about consistency, validity is about accuracy. What image comes to mind for you when you hear the word alcoholic? Are you certain that your image is similar to the image that others have in mind? If not, then we may be facing a problem of validity.
For a measure to have validity, it must accurately reflect the meaning of our concepts. Think back to when we initially considered measuring alcoholism by asking research participants if they have ever had a problem with alcohol. We realized that this might not be the most reliable way of measuring alcoholism because the same person’s response might vary dramatically depending on how they are feeling that day. Likewise, this measure of alcoholism is not particularly valid. What is “a problem” with alcohol? For some, it might be having had a single regrettable or embarrassing moment that resulted from consuming too much. For others, the threshold for “problem” might be different. Perhaps a person does not believe that they have an alcohol problem, although they have had numerous embarrassing drunken moments. As you can see, there are countless ways that participants could define an alcohol problem. If we are trying to objectively understand how many of our research participants are alcoholics, then this measure may not yield any useful results. [1]
In the last paragraph, critical engagement with our measure for alcoholism “Do you have a problem with alcohol?” was shown to be flawed. We assessed its face validity or whether it is plausible that the question measures what it intends to measure. Face validity is a subjective process. Sometimes face validity is easy, as a question about height wouldn’t have anything to do with alcoholism. Other times, face validity can be more difficult to assess. Let’s consider another example.
Perhaps we’re interested in learning about a person’s dedication to healthy living. Most of us would probably agree that engaging in regular exercise is a sign of healthy living. We could measure healthy living by counting the number of times per week that a person visits their local gym, but perhaps they visit the gym to use the tanning beds, flirt with potential dates, or sit in the sauna. While these activities are potentially relaxing, they are probably not the best indicators of healthy living. Therefore, recording the number of times a person visits the gym may not be the most valid way to measure their dedication to healthy living.
In addition, this measure of healthy living is problematic because it is incomplete. Content validity assesses whether the measure includes all of the possible meanings of the concept. Think back to the previous section on multidimensional variables. Healthy living seems like a multidimensional concept that might need an index, scale, or typology to measure it completely. Our one question on gym attendance doesn’t cover all aspects of healthy living. Once you have created one, or found one in the existing literature, you need to assess for content validity. Are there other aspects of healthy living that aren’t included in your measure?
Let’s say you have created (or found) a good scale, index, or typology to measure healthy living. For example, a valid measure of healthy living might be able to predict future blood panel test scores. This is called predictive validity, and it means that your measure predicts things it should be able to predict. In this case, our measure predicts that if you have a healthy lifestyle, then a standard blood test administered in a few months would show healthy results. If we were to administer the blood panel measure at the same time as the scale of healthy living, we would be assessing concurrent validity. Concurrent validity is the similar to predictive validity, except that both measures are given at the same time.
Another closely related concept is convergent validity. In assessing for convergent validity, you should look for existing measures of the same concept, for example the Healthy Lifestyle Behaviors Scale (HLBS). If you give someone your scale and the HLBS at the same time, their scores should be similar. Convergent validity compares your measure to an existing measure of the same concept. If the scores are similar, then it’s likely that they are both measuring the same concept. Discriminant validity is a similar concept, except you would be comparing your measure to one that is entirely unrelated. A participant’s scores on your healthy lifestyle measure shouldn’t be statistically correlated with a scale that measures knowledge of the Italian language.
These are the basic subtypes of validity, though there are certainly others you can read more about. Think of validity like a portrait: Some portraits look just like the person they are intended to represent, but other representations like caricatures and stick drawings are not nearly as accurate. A portrait may not be an exact representation of how a person looks, but the extent to which it resembles the subject is important. The same goes for validity in measures: No measure is exact, but some measures are more accurate than others.
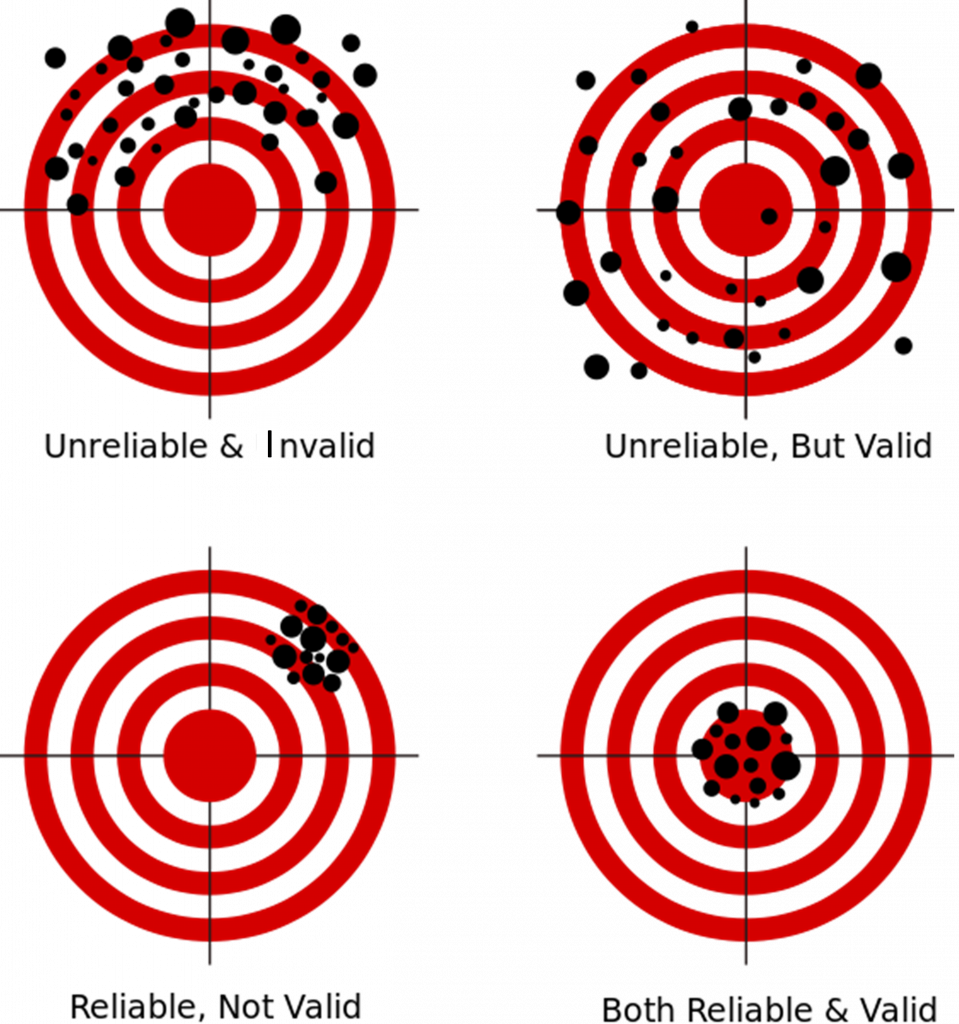
If you are still confused about validity and reliability, Figure 9.2 provides a visual representation. On the top left target, the shooter’s aim is all over the place. It is neither reliable (consistent) nor valid (accurate). The top right target shows an unreliable and inconsistent shot however it is centered around the target (accurate). The bottom left target demonstrates consistency, but the shooter’s aim is reliably off-target, and therefore invalid. The final bottom right target represents a reliable and valid result. The shooter hits the target accurately and consistently. This is what you should aim for in your research.
Trustworthiness and authenticity
The standards for measurement are different in qualitative and quantitative research for an important reason. Measurement in quantitative research is done objectively or impartially. That is, the researcher has minimal influence over the measurement process. They simply choose a measure, apply it, and read the results. Therefore, the accuracy and consistency depend on the measure rather than the researcher.
Differently, qualitative researchers are deeply involved in the data analysis process. There are no external measurement tools, like quantitative scales, rather the researcher is the measurement instrument. Researchers build connections between different ideas that participants discuss and draft an analysis that accurately reflects the depth and complexity of what participants have said. This is challenging for researchers, as it involves acknowledging their own various biases and allowing the meaning that participants shared to emerge as the data is read. This process is not concerned with objectivity, for there is always some subjectivity in qualitative analysis. We are more concerned with researchers rigorously engaging in the data analysis process.

For this reason, researchers speak of rigor in more personal terms. Trustworthiness refers to the “truth value, applicability, consistency, and neutrality” of the results of a research study (Rodwell, 1998, p. 96). [3] Authenticity refers to the degree to which researchers capture the multiple perspectives and values of their participants and foster change across participants and systems during their analysis. Both trustworthiness and authenticity contain criteria that help a researcher gauge the rigor with which the study was conducted.
When discussing validity and reliability, we must think about trustworthiness. Criteria for trustworthiness include credibility, dependability, and confirmability. Credibility refers to the accuracy of the results and the degree to which participants viewed them as important and believable. Qualitative researchers will often consult with participants before finalizing and publishing their results to make sure participants agree with them. They may also seek assistance from another qualitative researcher to review or audit their work. As you might expect, it’s difficult to view your own research without bias, so another set of eyes is often helpful. Unlike in quantitative research, the ultimate goal is not to find the Truth (with a capital T) using a predetermined measure, but to create a credible interpretation of the data.
Credibility is akin to validity, as it mainly speaks to the accuracy of the research product. On the other hand, the criteria of credibility is similar to reliability. As we just reviewed, reliability is the consistency of a measure. If you give the same measure each time, you should get similar results. However, qualitative research questions, hypotheses, and interview questions may change during the research process. How can reliability be achieved under such conditions?
The procedures of qualitative data analysis include the principle of emergence, so there isn’t a need for everyone to get the exact same questions each time. Indeed, because qualitative research understands the importance of context, it would be impossible to control all things that make a qualitative measure the same when given to each person. The location, timing, or even the weather can influence participants to respond differently. To assess dependability, researchers ensure that the study followed proper qualitative procedures and they also justify, describe, and account for any changes that emerge during the research process in their final report. Researchers should keep a journal or log to document any changes to their methodology as well as their justification. In addition, researchers may consult another qualitative researcher to examine their logs and results to ensure dependability.
Finally, the criteria of confirmability refers to the degree to which the results reported are linked to the data obtained from participants. While it is possible for another researcher to view the same data and come up with a different analysis, confirmability ensures that a researcher’s results are grounded in what participants said. Another researcher should be able to read the results of your study and trace each point back to something specific that one or more participants shared. This process is called an audit.
The criteria for trustworthiness were created as a reaction to critiques of qualitative research as unscientific (Guba, 1990). [4] They demonstrate that qualitative research is equally as rigorous as quantitative research. Subsequent scholars conceptualized the dimension of authenticity without referencing the standards of quantitative research at all. Instead, they wanted to understand the rigor of qualitative research on its own terms. What comes from acknowledging the importance of the words and meanings that people use to express their experiences?
While there are multiple criteria for authenticity, the most important for undergraduate social work researchers is fairness. Fairness refers to the degree to which “different constructions, perspectives, and positions are not only allowed to emerge, but are also seriously considered for merit and worth” (Rodwell, 1998, p. 107). Depending on their design, qualitative researchers may involve participants in the data analysis process, attempt to equalize power dynamics among participants, and help negotiate consensus on the final interpretation of the data. As you can see from the talk of power dynamics and consensus-building, authenticity attends to the social justice elements of social work research.
After fairness, the criteria for authenticity become more radical, focusing on transforming individuals and systems examined in the study. For our purposes, it is important for you to know that qualitative research and measurement are conducted with the same degree of rigor as quantitative research. The standards may be different, but they speak to the goals of accurate and consistent results that reflect the views of the participants in the study.
Key Takeaways
- Reliability is a matter of consistency.
- Validity is a matter of accuracy.
- There are many types of validity and reliability.
- Qualitative researchers assess rigor by using the criteria of trustworthiness and authenticity.
- Both quantitative and qualitative research are equally rigorous, but the standards for assessing rigor differ between the two.
Glossary
Authenticity– the degree to which researchers capture the multiple perspectives and values of participants in their study and foster change across participants and systems during their analysis
Concurrent validity– if a measure is able to predict outcomes from an established measure given at the same time
Confirmability– the degree to which the results reported are linked to the data obtained from participants
Content validity– if the measure includes all of the possible meanings of the concept
Convergent validity– if a measure is conceptually similar to an existing measure of the same concept
Credibility– the degree to which the results are accurate and viewed as important and believable by participants
Dependability– ensures that proper qualitative procedures were followed and that any changes that emerged during the research process are accounted for, justified, and described in the final report
Discriminant validity– when a measure is not related to measures to which it shouldn’t be statistically correlated
Face validity– if it is plausible that the measure measures what it intends to
Fairness– the degree to which “different constructions, perspectives, and positions are not only allowed to emerge, but are also seriously considered for merit and worth” (Rodwell, 1998, p. 107)
Internal consistency reliability– degree to which scores on each question of a scale are correlated with each other
Inter-rater reliability– the degree to which different observers agree on what happened
Predictive validity– if a measure predicts things it should be able to predict in the future
Reliability– a measure’s consistency
Test-retest reliability– if a measure is given multiple times, the results will be consistent each time
Trustworthiness– the “truth value, applicability, consistency, and neutrality” of the results of a research study (Rodwell, 1998, p. 96)
Validity– a measure’s accuracy
- Of course, if our interest is in how many research participants perceive themselves to have a problem, then our measure may be just fine. ↵
- Figure 9.2 was adapted from Nevit Dilmen’s “Reliability and validity” (2012) Shared under a CC-BY 3.0 license Retrieved from: https://commons.wikimedia.org/wiki/File:Reliability_and_validity.svg I changed the word unvalid to invalid to reflect more commonly used language. ↵
- Rodwell, M. K. (1998). Social work constructivist research. New York, NY: Garland Publishing. ↵
- Guba, E. G. (1990). The paradigm dialog. Newbury Park, CA: Sage Publications. ↵

.jpg){kind=link}